






Olá pessoal, neste post iremos aprender como construir nosso próprio aplicativo de transcrição de áudio em texto, usando apenas Javascript e algumas API’s nativas dos navegadores.
Para deixar nosso aplicativo com um visual super bacana, e construí-lo rapidamente, utilizaremos também o Quasar Framework.
Se você é um desenvolvedor Front-end e ainda não ouviu falar sobre o Quasar, leia esse post sobre a versão 1.0 recém lançada.
Criando o projeto
O primeiro passo, é saber se nosso ambiente já está configurado. Os requisitos necessários são:
- Node >=8 e NPM >=5
- Quasar CLI
Agora vamos criar nosso projeto com Quasar CLI, executando o seguinte comando no seu cmd favorito:
quasar create quasar-speech-apiApós selecionar as opções desejadas no projeto e finalizar a instalação podemos levantar nosso ambiente de desenvolvimento usando o comando:
quasar devConhecendo a Speech API
A Web Speech API permite incorporar dados de voz em aplicativos da web. A nossa aplicação vai utilizar 2 recursos da Web Speech API : SpeechSynthesisUterrance (Texto para Fala) e SpeechRecognition (Reconhecimento de Fala Assíncrona).
SpeechSynthesisUtterance
A SpeechSynthesisUtterance representa um pedido de fala e é compatível com os seguintes browsers


Para poder testar, abra o console de seu navegador(um que esteja na lista de compatibilidade) e execute:
speechSynthesis.speak(new SpeechSynthesisUtterance('Esse é um pedido de fala executado'))Você também pode configurar algumas propriedades:
- lang – defina o idioma (os valores usam uma tag de idioma BCP 47, como
en-USoupt-BR); - pitch – obtém e define o tom na qual a expressão será dita aceita entre [0 e 2 ], o padrão é 1;
- rate– definir a velocidade, aceita entre [0,1-10], o padrão é 1;
- text – em vez de configurá-lo no construtor, você pode passá-lo como uma propriedade. O texto pode ter no máximo 32767 caracteres;
- voice – define a voz (mais sobre isso abaixo);
- volume – define o volume, aceita entre [0 – 1], o padrão é 1;
Faça o teste no console de seu navegador:
const utterance = new SpeechSynthesisUtterance('Esse é um pedido de fala executado')
utterance.pitch = 1.5
utterance.volume = 0.5
utterance.rate = 8
speechSynthesis.speak(utterance)SpeechRecognition
A SpeechRecognition é a interface para o serviço de reconhecimento. Atualmente essa é uma tecnologia experimental, então sua compatibilidade ainda é bastante limitada com os navegadores do mercado.
Atualmente disponível no Chrome a partir da versão 33 e no WebView. Ou seja, se você também construir um aplicativo híbrido que utilize uma webview, também será compatível com essa API.
Aqui você pode conferir um exemplo interessante onde o fundo se modifica caso a cor falada esteja na lista pré definida. Basta clicar na tela e falar:
https://mdn.github.io/web-speech-api/speech-color-changer/
Criando Boot Files
Iremos criar um arquivo Boot em nosso projeto Quasar. Mas antes precisamos entender o que de fato ele faz.
Um arquivo de inicialização(boot) é um arquivo JavaScript simples que pode, opcionalmente, exportar uma função. O Quasar chamará a função exportada quando inicializar o aplicativo e, além disso, passará um objeto com as seguintes propriedades para a função:
- app – Objeto com o qual o componente raiz e instanciado pelo Vue
- router – instância do Vue Router de ‘src/router/index.js’
- store – instância do aplicativo Vuex Store
- Vue – É como se fizéssemos import Vue from ‘vue’ e está lá por conveniência
- ssrContext – Disponível apenas no lado do servidor, se estiver construindo uma aplicação SSR
Bem, agora iremos criar o nosso próprio boot chamado de speech.js no diretório /src/boot.
import { Loading, QSpinnerAudio, QSpinnerBars } from 'quasar'
export default async ({ Vue }) => {
Vue.prototype.$speechTalk = (lang = 'pt-BR', text) => {
return new Promise((resolve, reject) => {
let speech = new SpeechSynthesisUtterance()
// Set the text and voice attributes.
speech.lang = lang
speech.text = text
speech.volume = 1
speech.rate = 1
speech.pitch = 1
setTimeout(() => {
window.speechSynthesis.speak(speech)
}, 300)
speech.addEventListener('start', () => {
Loading.show({
delay: 0,
spinner: QSpinnerAudio, // ms,
backgroundColor: 'primary'
})
})
speech.addEventListener('end', () => {
Loading.hide()
resolve(true)
})
})
}
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition
const recognition = SpeechRecognition ? new SpeechRecognition() : false
Vue.prototype.$speechToText = {
start: (lang = 'pt-BR', continuous = false) => {
return new Promise((resolve, reject) => {
let text = ''
setTimeout(() => {
Loading.show({
// delay: 400,
spinner: QSpinnerBars, // ms,
backgroundColor: 'primary',
message: 'Aguardando áudio',
messageColor: 'white'
})
recognition.lang = lang // this.voiceSelect
recognition.continuous = continuous
recognition.start()
}, 400)
recognition.onresult = (event) => {
let current = event.resultIndex
// Get a transcript of what was said.
let transcript = event.results[current][0].transcript
// Add the current transcript to the contents of our Note.
// var noteContent += transcript
text += transcript
resolve(text)
}
recognition.onspeechend = (event) => {
// if (continuous) {
reject(false)
// }
}
recognition.nomatch = () => {
reject(false)
}
recognition.onend = () => {
text = ''
Loading.hide()
if (!continuous) {
reject(false)
}
}
})
},
stop: () => {
recognition.stop()
}
}
}Neste arquivo adicionamos 2 propriedades a instância Vue. A propriedade $speechTalk e $speechToText.
A $speechTalk irá disparar a api SpeechSynthesisUtterance e iniciar a fala do assistente. Para isso precisamos passar 2 parâmetros:
- lang – onde passaremos o idioma escolhido para a narração.
- text – o texto que será narrado
Além disso, conseguimos fazer com que as propriedades sejam Promises, já que é possível identificar os eventos de inicialização e finalização(start e end).
Na $speechToText passaremos os parâmetros:
- lang – onde passamos o idioma escolhido para a fala.
- continuous – quando true, fica constantemente recebendo eventos e detectando a fala e convertendo para texto
Temos 2 possibilidades com o $speechToText, o start para iniciar o processo de captura e o stop para forçar a parada.
Criando nossa Página(Page)
No diretório src/pages alteramos o Index.vue para o seguinte código:
<template>
<q-page class="container">
<div class="row q-col-gutter-md q-pt-md">
<q-select
outlined v-model="voiceSelect"
:options="optionsVoice"
label="Idiomas"
class="col-12"
emit-value
map-options/>
<div class="col-6 q-pt-md">
<q-btn
push color="primary"
round size="lg" icon="keyboard_voice"
class="float-right"
@click="record()"/>
</div>
<div class="col-6 q-pt-md">
<q-btn
push color="primary"
round size="lg" icon="play_arrow"
@click="playAudio()"/>
</div>
<div class="col-12 text-center">
<q-toggle
v-model="continuous"
label="Contínuo"
left-label
/>
</div>
<div class="col-12 q-pa-xl">
<q-input
v-model="text"
autogrow
label="Texto"
clearable
outlined/>
</div>
<div class="col-12 q-pa-lg text-caption">
<div class="text-bold">Instruções:</div>
<div>Escolha seu idioma para que o assistente escreva corretamente sua fala.</div>
<div>Aperte no botão microfone
<q-btn dense color="primary" round size="xs" icon="keyboard_voice" />
para iniciar a captura de fala, e autorize seu dispositivo a utilizar o microfone.
</div>
<div>
Ao aparecer a tela com a mensagem "Aguardando Áudio" diga a frase que deseja que seja transcrita.<br>
Ao finalizar, sua fala aparecerá no campo de Texto.
</div>
<div>Caso queira ouvir o texto, basta apertar no botão play <q-btn dense color="primary" round size="xs" icon="play_arrow" />. </div>
</div>
</div>
<q-page-sticky v-if="btnStop" position="bottom-right" :offset="[15, 18]" style="z-index: 10000">
<q-btn fab icon="stop" color="negative" @click="stop()" />
</q-page-sticky>
</q-page>
</template>
<style>
</style>
<script>
export default {
name: 'PageIndex',
data () {
return {
text: '',
voiceSelect: 'pt-BR',
optionsVoice: [],
continuous: false,
btnStop: false
}
},
mounted () {
this.setVoices()
},
methods: {
setVoices () {
let id = setInterval(() => {
if (this.optionsVoice.length === 0) {
this.voicesList()
} else {
clearInterval(id)
}
}, 50)
},
voicesList () {
let teste = window.speechSynthesis
this.optionsVoice = teste.getVoices().map(voice => ({
label: voice.name, value: voice.lang
}))
},
playAudio () {
this.$speechTalk(this.voiceSelect, this.text)
},
record () {
this.btnStop = true
this.$speechToText.start(this.voiceSelect, this.continuous)
.then((suc) => {
this.text += ' ' + suc
if (this.continuous) {
this.record()
}
// this.btnStop = false
})
.catch(() => {
this.btnStop = false
})
},
stop () {
this.$speechToText.stop()
this.btnStop = false
}
}
}
</script>
Antes de tentar exibir o projeto é necessário habilitar alguns componentes em nosso quasar.conf.js.
components: [
'QLayout',
'QHeader',
'QDrawer',
'QPageContainer',
'QPage',
'QToolbar',
'QToolbarTitle',
'QBtn',
'QIcon',
'QList',
'QItem',
'QItemSection',
'QItemLabel',
'QInput',
'QSelect',
'QSpinnerBars',
'QSpinnerComment',
'QBadge',
'QImg',
'QAvatar',
'QScrollArea',
'QPageSticky',
'QToggle'
],No mounted() da nossa página, é disparado o método setVoices(), este método serve para recuperar os tipos de idiomas disponíveis no navegador, e são armazenados no parâmetro optionsVoice para serem exibidos no select de Idiomas.
O método playAudio(), dispara o narrador. Ele utiliza o idioma selecionado e o texto da textarea para enviar ao $speechTalk.
O método record irá ativar o $speechToText e ficar aguardando uma fala em seu app. Para isso é passado ao método o idioma selecionado e o parâmetro “continuous” que como vimos anteriormente, deixa o ouvinte constante ou não.
Por fim temos o método stop(), que é usado em um botão quando o modo continuo for ativado.
O resultado de nosso app é este:
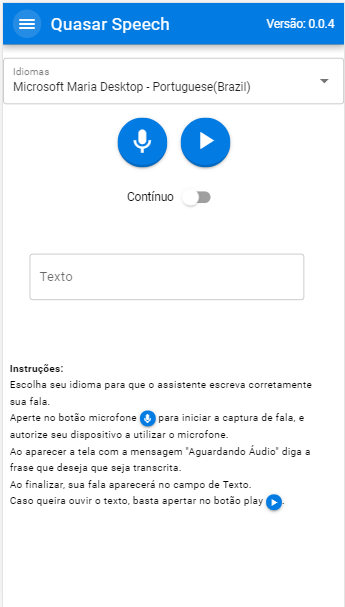
Não precisamos instalar nenhuma dependência externa em nossa aplicação. Isso mostra que os navegadores evoluíram muito e possuem muitos recursos poderosos e pouco utilizados por desenvolvedores.
O projeto está atualizado no meu github e você pode clona-lo ou baixa-lo através do link:
https://github.com/patrickmonteiro/quasar-speech-api
Ou acessar a DEMO: https://quasarspeechapi.surge.sh/#/
Referências:
https://flaviocopes.com/speech-synthesis-api/
https://developer.mozilla.org/pt-BR/docs/Web/API/SpeechSynthesisUtterance
https://developer.mozilla.org/en-US/docs/Web/API/Web_Speech_API









